
ICML 2026|FusionRoute:从专家路由到自我修正,一种新的多LLM协作范式
本文由 Nuoya Xiong 、 Yuhang Zhou 、 Hanqing Zeng 、 Zhaorun Chen 、 Furong Huang 、 Shuchao Bi 、 Lizhu Zhang 、 Zhuokai Zhao 等研究者合作完成。论文第一作者 Nuoya Xiong 为 CMU 计算机学院二年级博士生,研究方向为大语言模型的后训练与强化学习,本工作完成于其在 Meta 实习期间。该项目由 Meta AI 的 Zhuokai Zhao 和 Lizhu Zhang 共同领导,合作者还包括来自 Meta TBD 团队的 Shuchao Bi 以及 University of Maryland 的 Furong Huang 教授。
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径: 通过多个专家模型的协作来完成生成任务 。
这一思路背后的直觉并不复杂:现实中往往不存在一个在所有任务上都同样出色的模型,而是会涌现出大量各有所长的 “ 专家模型 ” 。例如,专门针对数学数据训练的模型更擅长复杂推理,代码模型在程序生成和语法结构上表现更稳定,而指令微调模型则更擅长对话理解与交互表达。与其追求一个 “ 无所不能 ” 的统一大模型,不如将多个领域专家进行组合,让它们在各自擅长的子问题上发挥作用。这种方式不仅能够更充分地利用已有模型的能力,也避免了单一模型在所有维度上都需要做到极致所带来的训练成本与优化难度。
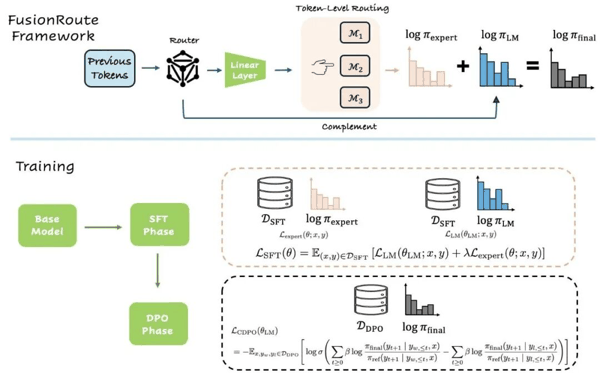
针对这一方向,论文提出了 FusionRoute ,一种基于 token-level 路由的多 LLM 协作范式 。不同于以往在整段生成中选择单一模型, FusionRoute 训练一个路由模型, 在每一步生成时,使用该路由模型动态判断当前这个 token 更适合由哪个专家模型来生成。这种更细粒度的路由方式,使模型能够在同一段生成过程中灵活切换不同专家,在推理、代码生成和自然语言表达等不同子任务之间进行动态分工,从而更充分地发挥各个模型的优势。
在此基础上, FusionRoute 进一步利用路由器本身的理解能力,引入了一种 补充生成( complementary generation )机制 。除了进行 expert 选择之外,路由器还会为当前 token 提供额外的生成信号,并与 expert 的输出共同作用,形成最终结果。由此,路由器不再只是一个 “ 选择器 ” ,而成为生成过程中的参与者,进一步提升了整体表达能力。
相比 sequence-level 的协作方式, FusionRoute 具有更高的灵活性和更细粒度的控制能力。同时,不同于传统 MoE , FusionRoute 的专家可以是结构各异、已经训练完成的独立模型,从而在实际部署中更加灵活、也更具工程可行性。
 论文标题:
论文标题:
Token-Level LLM Collaboration via FusionRoute
arXiv 地址:
https://arxiv.org/pdf/2601.05106
代码地址:
https://github.com/xiongny/FusionRoute
以往的 sequence-level collaboration 在整段生成完成后再进行模型融合,讨论或选择。多个模型需要生成完整回答,再通过 reranking 或辩论得到最终结果。这种方式虽然简单,但存在明显问题:一方面计算开销较大(需要多次完整生成),另一方面协作粒度较粗,因此往往比较低效。
相比之下, 以往的 token-level collaboration 将协作粒度细化到每一步生成,通过在多个模型之间进行 token 级别的选择来决定下一个 token 。这种方法能够实现更灵活的专家切换,但其核心仍然是 “ 从多个候选中进行选择 ”。 因此,一旦选择结果不稳定或某一步选择出现偏差,误差会在后续生成中不断累积,导致整体生成过程不够稳定。文章也通过理论推导,证明了在仅有 single policy coverage 的合理假设下,纯粹基于专家选择的 token-level 路由存在本质上的 " 不可识别性 "—— 即便存在一条最优路径,仅凭沿最优轨迹观测到的 Q 值也无法可靠地识别出哪个专家应被选中,揭示了以往 token-level 协作的主要瓶颈。
FusionRoute 的关键思路是引入了一个可训练的 router 模块,提供两个功能:
1、对于 decoding 过程中的每个 token ,输出一个路由权重。系统之后会选择权重最高的专家进行这个 token 的生成。
2、输出 router logits ,利用 router 的理解能力对 expert 的 token logits 进行补充生成。最终的 logits 合并专家 logits 和 router logits 。这种设计使得最终生成不再仅依赖于单一专家的输出,而是融合了 expert 能力与全局理解,从而在保持细粒度协作的同时,显著提升了生成的稳定性与鲁棒性。
路由模型训练
在训练上, FusionRoute 无需对专家进行额外微调,而是固定已有的专家,仅训练一个轻量级的 router 模块。训练分为两个阶段:
1、首先,在监督微调( SFT )阶段,训练 router 使其能够在给定上下文下学习如何组合不同专家的输出。具体而言, router 自身会生成补充的 logits ,并通过 next-token cross-entropy loss 进行优化;同时, router 输出的路由权重与多个 expert 提供的 token 分布加权得到最终的聚合 logits ,并通过专家选择损失对路由线性层进行端到端优化。值得注意的是,论文在路由损失中只保留了 " 信息性 token"—— 即不同专家预测结果存在分歧的位置,避免标点、虚词等所有专家都能正确预测的 token 主导梯度,从而让路由真正学到的是专家之间的能力差异。经过这一阶段, router 已能够学习基本的专家选择与语言能力。
2、第二个阶段是训练 router logits 的补充生成能力( CDPO )。具体来说, FusionRoute 将 router logits 和专家 logits 合并起来,然后在偏好数据集上计算 token 的概率,并基于 DPO 进行优化。这里的一个关键设计是,专家提供的 log-ratio 项被作为不传梯度的 " 偏置项 " 处理 —— 当专家本身已经能给出强策略时,该偏置项较大, router 自身的梯度自然变小;当专家薄弱时, log-ratio gap 缩小, router 会获得更大的修正信号。这种机制让 router 在专家失效的位置才发力,自动实现 " 按需补充 " 。另一大挑战在于,单独训练 router logits 的补充生成能力会使得 router 的参数与输出路由权重的线性层不匹配。由此, FusionRoute 设计了一种 混合训练策略 ,将监督微调( SFT )与基于偏好的优化( CDPO )结合在同一训练流程中 。
实验 1: 在多个领域上显著提升了综合能力