
花了1000倍的token,效果可能却没有更好:AI Agent的“隐性账单”长什么样
如今的 AI Agent 正在大规模落地,其中应用最广且最受关注的当数 Claude Code,Codex,Cursor 这类 coding agent。过去的一年里,这类 coding agent 产品迭代迅速,在一年内将在 swe-bench- verified 的准确率提高到了 78%+。
然而,相比简单的代码推理或者和代码相关的聊天,coding agent 的 token 消耗也极为显著。在使用这种 coding agent 的过程中,最常听到的抱怨也是:“为什么它解决问题这么啰嗦”,“为什么要这么长篇大论”,以及 “为什么我的 credits 这么快又用完了?”
这些抱怨的背后暴露出当前 coding agent 的几大问题:
1. 不透明: coding agent 消耗 token 的习惯不清晰,行为模式以及不同模型之间的差异不透明;
2. 不保底:在任务执行前难以知道任务成功与否,但不论是否成功,都要支付相应开销;
3. 不可预测:人类估计的问题难度真的和实际的 token 消耗匹配吗?agent 能否自己判断问题会消耗多少 token 呢?
针对这些问题,来自密歇根大学、斯坦福大学等单位的研究者,使用开源的 OpenHands agent 框架,分析了 8 个 frontier 模型在 swe-bench-verified 上的轨迹,第一次给出了一份系统性的解答。

论文标题: HowDoAIAgentsSpendYourMoney? AnalyzingandPre dicting Token Consumption in Agentic Coding Tasks
arXiv 论文:https://arxiv.org/pdf/2604.22750
项目网站:https://longjubai.github.io/agent_token_consumption/
Agentic Coding 有多贵?
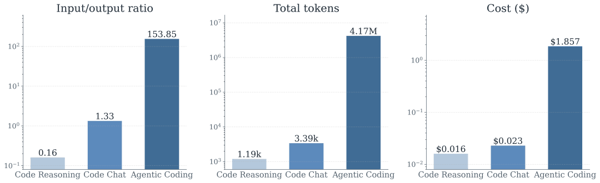
论文首先比较了和 coding 相关的 3 种任务:代码推理(和代码相关的单论对话推理任务),代码问答对话(关于代码问题的多轮对话聊天),以及 swe-bench 上的 agentic 代码任务。结果发现,agentic coding 任务在平均输出输入 token 比,平均总 token 消耗,以及平均金钱消耗,均指数级高于其他两种任务。
这源自于 agentic coding 任务的多轮交互和巨大而复杂的上下文管理:巨量的代码查询,文件输出都会被加入到对话历史中,导致消耗持续增加,并且 agent 会不断把历史上下文、工具输出反复喂给模型,导致输入输出比高达 154:1。这意味着 agentic coding 任务的成本结构与我们所熟悉的对话和推理任务有显著的不同。
Agentic Coding 的开销随机性高,
且花的越多不一定做得越好
论文统计了 swe-bench-verified 中 500 个问题的平均 token 消耗,并将消耗从小到大排序。从图中可以发现,最贵的任务可能比最便宜的任务多消耗约 700 万 token,并且越贵的任务 token 消耗的标准差也越大。
对同一任务的重复运行来说,通过计算最贵的一次运行和最便宜的一次运行的差异,结果发现即使是同一任务,最贵的运行仍可能比最便宜的运行贵 2 两倍左右。
进一步分析 token 消耗多少与准确率的关系,论文发现 更 多 的消耗并不能保证更高的准确率。
对于不同任务来说,论文根据平均 token 消耗的数量进行分组,并统计每组任务的准确率,结果发现 token 消耗更多的任务往往准确率较低。
对于同一个任务的不同运行来说,将 4 次运行按照 token 消耗排序,分成四个开销等级,然后统计每一个开销等级的准确率。结果发现:平均所有模型来看,最高的准确率并不出现在开销最高的时候,而是出现在较低开销时。当开销最低时,任务运行的准确率最低,当提高开销稍微提高时,准确率达到最高,继续增加开销,当开销第二高和最高时,准确率不增反减 —— 更多的资源消耗并没有带来更高的任务成功率。