
Claude Fable 5最难档零分!智能体的最后考试来了
这几天,Anthropic 的最新模型 Claude Fable 5 发布之后,在 AI 圈激起了不小的震动。
今天一早,大模型评测平台 Arena 放出了智能体基准测试(Agent Arena)的成绩:Fable 5(High)排名第一,OpenAI 的 GPT-5.5(xHigh)屈居第二。另外,在「确认成功率」和「可引导性」等两项指标上,Fable 5(High)也稳压 GPT-5.5(xHigh)。
从 Agent Arena 的跑分来看,Fable 5 的性能强悍可见一斑。该基准通过数百万个真实世界的长周期智能体任务来评估模型,需要调用网页搜索、文件系统、终端等工具,完成写代码、制作幻灯片、网页研究、构建应用以及分析文档等复杂工作流。
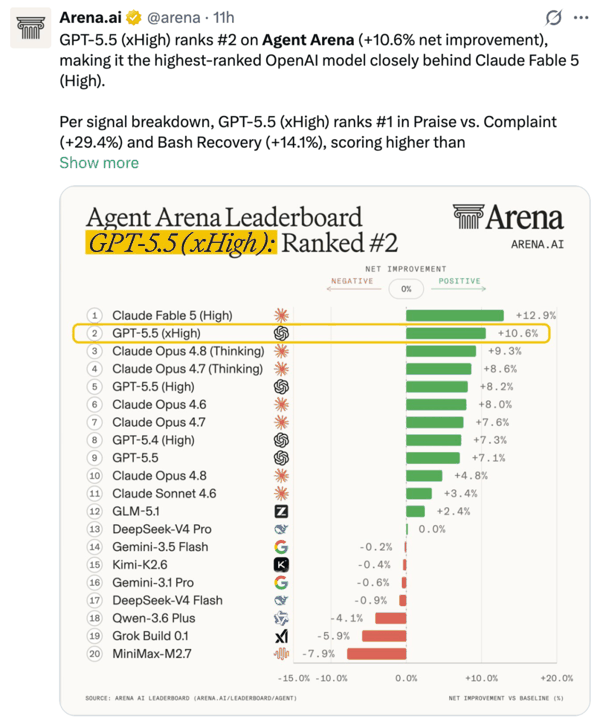
但与此同时,在另一个智能体基准测试中,Fable 5 败给了一个多月前发布的 GPT-5.5。
它是加州大学伯克利分校宋晓东(Dawn Song)教授团队开发的 ALE,全称为 Agents' Last Exam(智能体的最后考试),用来衡量 AI 智能体是否真的能够在广泛的真实世界领域中完成具有经济价值的工作 。
ALE 测试涵盖 55 个非体力职业,包含 1500 + 项任务,由来自 100 + 机构的 300+ 位专家贡献,覆盖科学、工程、医学、法律、金融、教育等多个领域。另外,该基准提供完整的 GUI + CLI 环境,并基于最终结果进行可验证评估。
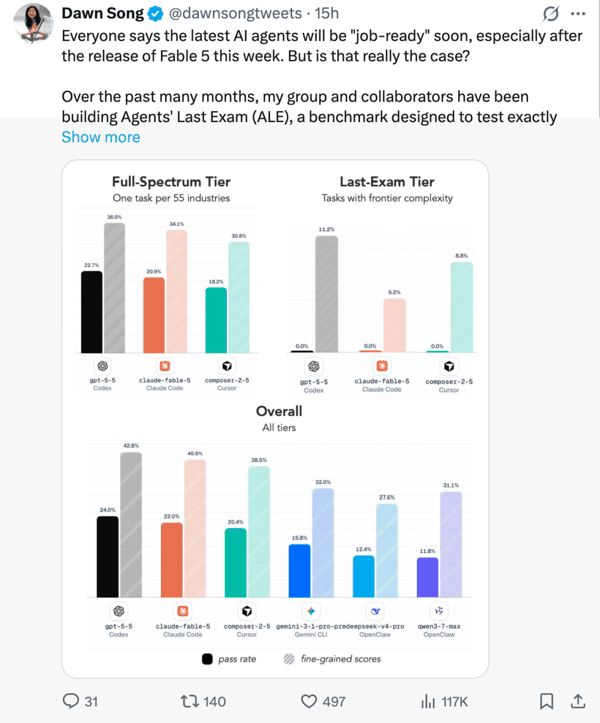
在 ALE 中,团队 评测了 Fable 5、GPT-5.5、Composer 2.5 以及其他前沿 Agent 系统 。结果既令人印象深刻,也足够让人冷静:
现在的 Agent 已经能够解决相当一部分专业任务,但当我们看向最难的那一类任务,也就是那些需要持续推理、深厚领域知识,以及长周期可靠执行的任务时,它们距离人类水平仍然很远。「有用的 Agent 时代已经到来,但真正能胜任工作的 Agent 时代,还没有。」
团队希望 ALE 能够成为一个新的参照系,帮助行业开发出能够在广泛领域中稳定完成经济价值工作的 Agent。
针对 Fable 5,ALE 的以下几点测试结果值得我们关注:
一是,在整体榜单中, GPT-5.5 凭借 24.0% 的通过率居于榜首,超越了 Fable 5 的 22.0% ;余下依次为 composer-2.5、Gemini-3.1-pro-preview、Deepseek-v4-pro 和 Qwen-3.7-Max。
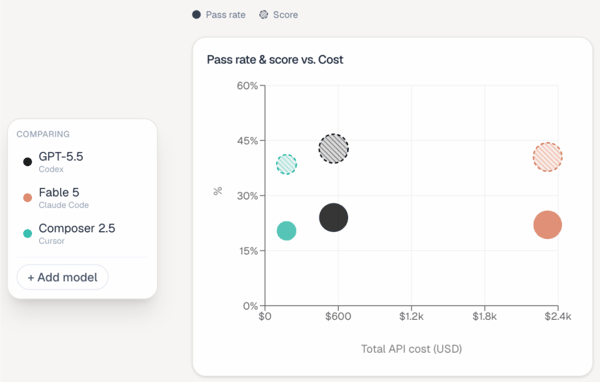
二是,成本差异巨大。虽然 Fable 5、GPT-5.5 和 Composer 2.5 的整体表现处在同一梯队,但每项任务的成本差异非常明显:Fable 5 平均每题花费约 $15.70,GPT-5.5 仅 $3.80,Composer 2.5 为 $1.33。
也就是说,在性能相近的情况下,Fable 5 每完成一项任务的成本大约是其他模型的 4 到 12 倍。
三是,最难一档全军覆没。 在最高难度「Last-Exam」档位,包括 Fable 5 在内的所有前沿 agent 通过率为 0% 。
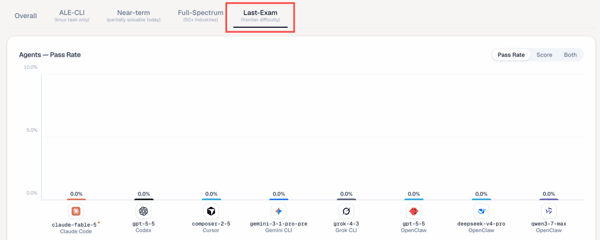
另外,ALE 中还有一个 仅支持命令行环境的子集 —— ALE-CLI 。
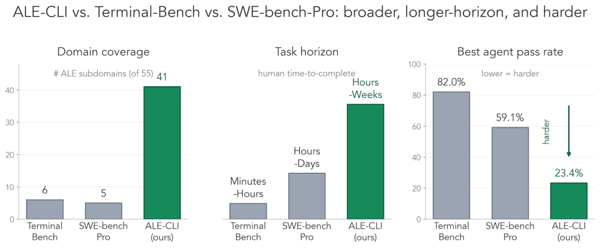
相比 Terminal-Bench 和 SWE-bench-Pro,它的覆盖范围更广、任务周期更长,难度也明显更高:
覆盖更广:ALE-CLI 的任务覆盖 ALE 55 个行业子领域中的 40 个;相比之下,Terminal-Bench 只覆盖 6 个,SWE-bench-Pro 只覆盖 5 个。
周期更长:人类完成这些任务通常需要数小时到数周,而不是几分钟到几天。
难度更高:表现最好的 Agent 通过率也只有 25.2%;相比之下,Terminal-Bench 上的最佳通过率为 82.0%,SWE-bench-Pro 为 59.1%。
这说明,Agent 离真正成熟还有很长的路要走,也还有很大的提升空间。
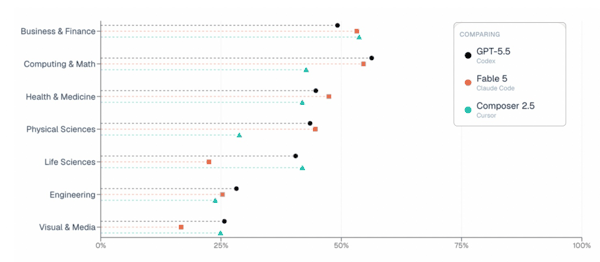
在谈到为什么 ALE 的结果和一些其他基准不太一样,尤其是 Fable 5?宋晓东表示,原因很简单:不存在一个在所有场景下都最强的 Agent。包括 Fable 5 在内,每个前沿模型都有自己擅长的领域,也都有表现吃力的领域。
总分会把 55 个职业、1500 多个任务的结果平均到一起,因此很多模型的分数会挤在相近区间。但真正重要的,不是平均分。真正有价值的信号在于:Agent 在哪里成功,在哪里失败,以及这些成败模式如何随领域而变化。同样的任务,不同模型失败的原因往往完全不同。
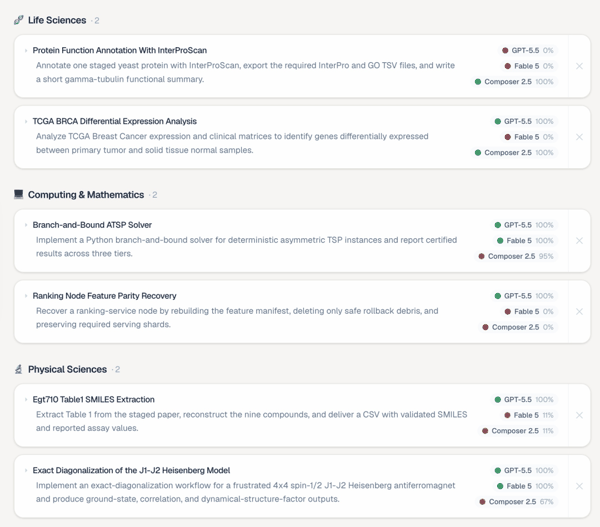
最常见的失败模式依然是一个熟悉的问题: Agent 还没有真正验证自己的工作,就先宣布任务完成。典型的完成回复往往是:「已完成,所有检查都通过了。」但实际输出可能缺少必要文件、统计数量有误、遗漏关键字段,或者违反了任务说明中明确写出的约束条件。
ALE 研究介绍

网站: https://agents-last-exam.org
任务示例: https://agents-last-exam.org/demo
排行榜: https://agents-last-exam.org/leaderboard
论文: https://arxiv.org/abs/2606.05405
ALE 是一个包含 1000 多个任务实例的基准测试,覆盖 55 个子领域和 13 个行业集群,由来自 100 + 机构的 300 + 位专家贡献。
为了确保行业覆盖足够广泛且具有代表性,专家顾问委员会会梳理各个领域的工作流图景,并基于 O*NET / SOC 2018 职业分类体系,识别具有经济意义的工作流类型。
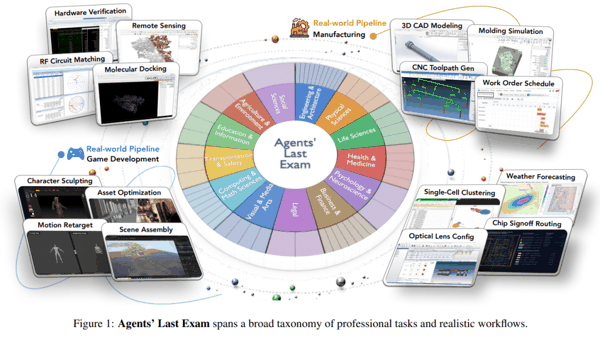
ALE 任务工作流来自真实的专业实践。它并不是凭空设计合成场景,而是由专家提供他们已经完成过的真实项目。这些项目在被纳入基准之前,还要经过多轮质量控制,包括初步审核、工程师试运行,以及专家委员会的最终同行评审。
大多数任务都要求智能体使用计算机,并在 GUI 交互和 CLI 操作之间来回切换。GUI 交互包括桌面应用、浏览器和特定领域软件;CLI 操作包括 shell 脚本、代码执行和文件处理。
这意味着,ALE 要求智能体同时具备多种能力,而这些能力在现有基准中往往是被分开测试的。
ALE 的目标评测对象是 GCUA(Generalist Computer-Use Agent)智能体,例如 Claude Code 或 Codex。这类智能体能够在同一个行动循环中结合视觉感知、代码执行、工具使用和长周期规划。按照设计,ALE 的任务形态覆盖范围要大于仅测试 GUI 的基准,例如 OSWorld,也大于仅测试 CLI 的基准,例如 Terminal-Bench 。
在任务收集上,ALE 不是随便收集一些任务来考验 AI,而是要求任务必须满足三个条件:
代表性。工作流应当符合真实的专业实践,并使用领域专家实际会使用的软件。例如,建筑领域专家在把 2D 蓝图转换为 3D 模型时,通常会使用 SolidWorks 或 Rhino,而不是 AutoCAD。
复杂性。一项任务应当是端到端的交付物,需要专家投入相当时间完成,而不只是几个简单的 UI 操作。关键区别在于:这是一个工作流,还是一个单一动作。
可验证性。输出结果应当能够接受确定性检查,或者能够按照与可观察产物绑定的明确评分细则进行评估。最理想的情况是,交付物具有确定性,可以直接与参考输出进行比较。即使无法做到精确匹配,判断也应当能够还原为对某个可测量产物的评估。
另外,ALE 中的任务不是由普通众包工人来提供;而是来自领域专业人士的真实日常工作,并经过严格筛选,以确保真实性、复杂性和技术可执行性,共包含五道关卡。