
从贝叶斯到大语言模型:一文详解「时序点过程」近年进展
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。
神经元在某个瞬间放电,社交平台上一条帖子突然被转发,地震之后余震接连发生,交易系统里买卖订单以毫秒级速度涌入。这些事件既有发生时间,也可能带有类型、文本、空间位置、图像或其他上下文信息;它们彼此影响,却又不服从传统时间序列的整齐采样假设。
这类数据,正是 时间点过程(Temporal Point Processes, TPPs)试图建模的对象。
近日,来自 中国人民大学、广东工业大学、东南大学 等机构的研究者在 TMLR 发表综述论文 《Advances in Temporal Point Processes: Bayesian, Neural, and LLM Approaches》,系统回顾了时间点过程近年来的进展。
 与以往侧重统计模型或神经 TPP 的综述不同,这篇论文把 Bayesian TPP、Neural TPP、LLM-based TPP、训练方法、应用场景和开放挑战放在同一个框架下讨论,覆盖文献一直更新到 2025 年。
与以往侧重统计模型或神经 TPP 的综述不同,这篇论文把 Bayesian TPP、Neural TPP、LLM-based TPP、训练方法、应用场景和开放挑战放在同一个框架下讨论,覆盖文献一直更新到 2025 年。
 论文标题:Advances in Temporal Point Processes: Bayesian, Neural, and LLM Approaches
论文标题:Advances in Temporal Point Processes: Bayesian, Neural, and LLM Approaches
作者:Feng Zhou、Quyu Kong、Jie Qiao、Cheng Wan、Yixuan Zhang、Ruichu Cai
论文链接:https://openreview.net/forum?id=SXgGKkShhT
为什么还需要重新梳理 TPP?
TPP 并不是一个新概念。Poisson 过程、Hawkes 过程、自校正过程等经典模型在统计学中已经有很长历史,并被用于电话呼叫到达、地震余震、金融交易、神经 spike train、社交网络传播等任务。
但过去几年,TPP 的研究对象和方法都发生了变化。
首先,传统参数模型可解释,但表达能力有限。Hawkes 过程可以直观描述「过去事件提高未来事件发生概率」的自激效应,但真实世界中的事件影响往往非线性、非平稳、多类型且伴随复杂上下文。
其次,深度学习让 TPP 变得更灵活。RNN、LSTM、Transformer、ODE/SDE、diffusion 等模型被引入事件序列建模后,研究者可以用更强的表示学习能力拟合复杂动态。
第三,大语言模型开始改变 TPP 的边界。过去的 TPP 多半只关心时间和事件类型,而现实事件往往还包含文本、图像、外部知识与语义关系。LLM 的出现让「预测下一个事件」扩展为「理解一段带时间戳的多模态事件历史」。
因此,这篇综述把近年来的 TPP 进展概括为三条主线:
Bayesian TPP: 强调不确定性量化和原则化推断;
Neural TPP: 强调表达能力、可扩展性和端到端预测;
LLM-based TPP: 强调语义理解、多模态建模和更开放的时间推理任务。
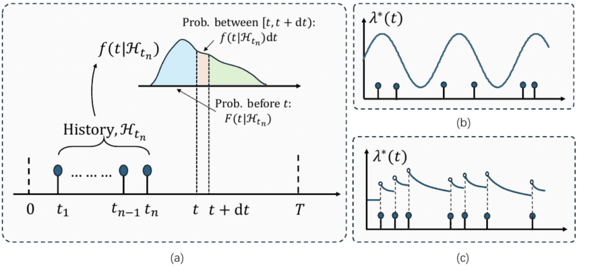
TPP 的核心:用强度函数描述「下一件事何时发生」
如果把一个事件序列写成t1, t2, ..., tN,TPP 建模的就是这些时间点在连续时间窗口内如何产生。更一般地,每个事件还可以带有 mark,也就是事件类型,例如 ((t1, k1), ..., (tN, kN))。
论文首先回顾了 TPP 的两个基本表述:条件密度函数和条件强度函数。后者是 TPP 中最核心的概念。直观来说,条件强度函数回答这样一个问题:
在已经观察到过去所有事件的前提下,未来某个很短时间窗口里发生某类事件的瞬时可能性有多大?
Poisson 过程假设事件之间彼此独立,可以用固定或随时间变化的强度描述。Hawkes 过程则进一步引入历史依赖:过去的事件会通过触发函数影响未来事件的发生概率。多变量 Hawkes 过程还能描述不同事件类型之间的相互激发关系,例如买单是否会影响卖单,某个用户的发帖是否会引发其他用户转发。
也正因为这种 「历史影响未来」的机制, TPP 不只适合做预测,也天然适合做因果发现,尤其是 Granger causality 意义下的事件类型依赖关系识别。
第一条路线:Bayesian TPP,让模型知道自己有多不确定
经典参数化 TPP 的问题在于,研究者需要提前假设强度函数的形式。但现实数据常常太复杂,很难用固定函数描述。贝叶斯非参数 TPP 的核心思想是:不要把强度函数限制在某个有限维参数形式里,而是直接把强度函数本身当作无限维对象,并为其设置先验。
论文重点讨论了两类 Bayesian nonparametric TPP:
Bayesian nonparametric Poisson process
Bayesian nonparametric Hawkes process
在 Poisson 场景中,常见做法是用 Gaussian Process 作为函数先验,再通过 link function 保证强度非负。这样一来,模型不仅能拟合复杂的时间变化强度,还能给出后验不确定性。但代价也很明显: 推断非常困难。
论文指出,相关后验往往存在「双重不可解」的问题,一方面似然里包含对时间的积分,另一方面还需要对函数空间积分。因此,研究者发展了 MCMC、Laplace approximation、variational inference、Pólya-Gamma 数据增强等方法来近似推断。
在 Hawkes 过程中,难点进一步增加。因为强度函数通常由背景强度和触发函数两部分组成,二者在似然中耦合。一个常见技巧是引入 branching latent variable,用隐藏变量表示某个事件是由背景过程产生,还是由之前某个事件触发。引入这个变量后,Hawkes 似然可以拆解成与背景强度和触发函数相关的两个部分,从而更容易套用非参数 Poisson 过程中的推断技术。
这条路线的优点很清楚:可解释、能量化不确定性、与统计理论联系紧密。缺点也同样明确:推断复杂,扩展到大规模数据时成本较高。
第二条路线:Neural TPP,用深度模型提升表达能力
深度学习给 TPP 带来的直接变化,是用神经网络替代手工设计的强度函数或条件分布。论文把 Neural TPP 的主流架构分为几类。
第一类是 recurrent neural TPP。 早期代表工作使用 RNN 或 LSTM 逐个读取事件,把历史压缩成 hidden state,再用 hidden state 参数化下一个事件的时间和类型分布。
它的优势是在线预测效率高:历史状态更新完之后,预测下一步可以做到常数时间。但缺点是训练难以并行,长程依赖建模能力有限。论文也特别提到一个新的方向:将 RWKV、S4、Mamba 等高效序列模型与 TPP 结合。这些模型仍具备递归式结构的高效性,同时支持并行训练和长程依赖建模,有望改善传统 RNN-TPP 的可扩展性。
第二类是 autoregressive neural TPP, 典型代表是 Transformer TPP。Transformer 可以通过 self-attention 捕捉长距离事件依赖,并支持并行训练。2020 年之后,大量工作围绕 Transformer TPP 改进时间编码、mark 编码、注意力机制和条件强度函数设计。
但 Transformer 的代价也熟悉:训练复杂度通常随序列长度呈二次增长,长事件流上的时间和显存成本都很高。对于高频交易、日志监控这类超长序列场景,如何降低复杂度仍是关键问题。
第三类是 differential equation-based neural TPP。 RNN 和 Transformer 通常只在事件发生时更新隐藏状态,对事件间隔中的连续时间动态表达不足。ODE/SDE-based TPP 则让隐藏状态在无事件发生时连续演化,在事件发生时发生跳变,从而更自然地刻画连续时间中的条件强度变化。这类方法表达力强,但训练和采样都更慢,因为它们往往需要数值求解微分方程,并反复计算强度函数积分。
 此外,论文还讨论了 diffusion-based TPP。与传统自回归模型逐个预测未来事件不同,扩散模型尝试通过迭代去噪生成整段事件序列。这为长时域预测和序列模拟提供了新视角,但也带来计算开销大、时间一致性难保证、似然评估不直接等问题。
此外,论文还讨论了 diffusion-based TPP。与传统自回归模型逐个预测未来事件不同,扩散模型尝试通过迭代去噪生成整段事件序列。这为长时域预测和序列模拟提供了新视角,但也带来计算开销大、时间一致性难保证、似然评估不直接等问题。
不只模型结构,参数化方式也很关键
TPP 中一个容易被忽略的问题是: 神经网络到底应该预测什么? 最常见的做法是预测条件强度函数。但最大似然训练时,强度函数需要在时间窗口上积分,这在神经模型中通常没有闭式解,只能依赖数值积分,影响效率和精度。
因此,近年来不少工作转向 「intensity-free」建模, 直接参数化条件密度函数、条件分布函数或累计强度函数。
例如,用 log-normal mixture 直接建模下一个事件的时间分布,或者用单调神经网络 / 样条函数建模累计强度。这样可以避免数值积分,提高训练和采样效率。论文将这些参数化方式放在一起比较,提醒读者:Neural TPP 的进展不只是换一个更大的 backbone,也包括对概率建模目标本身的重新设计。
第三条路线:LLM-based TPP,事件流开始拥有语义
这篇综述最有新意的部分,是把 LLM-based TPP 纳入时间点过程研究版图。论文认为,LLM-based TPP 可以分为两类。
第一类是 LLM-inspired TPP。 它们并不直接用 LLM 取代 TPP 主干,而是借鉴 prompt learning、reasoning 等思想增强现有神经 TPP。例如 PromptTPP 使用可学习 temporal prompts 适应持续变化的数据分布;LAMP 则引入 LLM 的溯因推理能力,让模型为候选未来事件生成可能原因,再从历史事件中检索证据。
这类方法的优点是相对高效,能增强适应性或可解释性;局限是时间动态本身仍主要由传统神经 TPP 建模。
第二类是 direct LLM-TPP integration, 即直接把 LLM 作为事件序列的核心表示模型。TPP-LLM 将事件用文本描述表示,并通过时间嵌入注入时间信息,再用 LoRA 等参数高效微调方法适配事件预测任务。Language-TPP 则进一步把连续时间间隔编码为 byte-level tokens,让时间和语言进入同一 token 序列,由 LLM 统一建模。
 这种方向的意义在于,TPP 不再只处理「时间 + 类型」的二维事件,而开始处理带有自然语言描述、外部知识、多模态上下文的复杂事件流。
这种方向的意义在于,TPP 不再只处理「时间 + 类型」的二维事件,而开始处理带有自然语言描述、外部知识、多模态上下文的复杂事件流。
论文同时提醒,LLM-based TPP 正在扩展传统 TPP 的边界。经典 TPP 的核心是连续时间事件发生过程的概率律,任务通常包括似然建模、预测、模拟和因果结构发现。而 LLM 引入后,事件序列检索、问答、多模态推理等任务也被纳入讨论。这些任务很有价值,但不一定都是严格意义上的点过程问题。未来社区需要更清楚地区分:哪些任务本质上是 TPP,哪些任务只是把 TPP 作为更大时间推理系统中的一个组件。
数据集和评测:TPP 社区还缺一个真正统一的基准
模型越来越复杂之后,评测问题变得更加重要。论文指出,TPP 研究长期面临数据集碎片化、预处理不一致、训练 / 验证 / 测试划分不同、指标定义不统一等问题。这使得不同论文之间的性能比较并不总是可靠。
近年来,EasyTPP 等统一 benchmark 工具开始缓解这一问题,提供标准化预处理、模型实现、训练流程和评估脚本。论文认为,benchmark 标准化的重要性不亚于新模型本身,因为只有可比较、可复现的实验结果才能真正积累为社区知识。
TPP 的评测任务也在扩展:
next-event prediction: 预测下一个事件的时间和类型;
long-horizon prediction: 预测未来一段窗口内的多个事件;
semantic or multimodal tasks: 面向 LLM-based TPP 的检索、问答、多模态推理等任务;
causal discovery: 识别不同事件类型之间的 Granger 因果关系。
 论文总结了一个相对谨慎的经验判断:Transformer-based neural TPP 在复杂数据上的 next-event prediction 往往优于经典参数模型;直接建模条件密度或累计强度的模型通常训练更高效;长时域预测仍然困难;LLM-based 和 multimodal TPP 在语义理解任务上有优势,但在纯时间预测基准上的优势还没有那么明确。
论文总结了一个相对谨慎的经验判断:Transformer-based neural TPP 在复杂数据上的 next-event prediction 往往优于经典参数模型;直接建模条件密度或累计强度的模型通常训练更高效;长时域预测仍然困难;LLM-based 和 multimodal TPP 在语义理解任务上有优势,但在纯时间预测基准上的优势还没有那么明确。
应用:从预测下一次点击,到发现事件之间的因果链
TPP 的应用可以粗略分成两类: 事件预测和因果发现。
事件预测关注未来会发生什么、什么时候发生、属于哪一类。典型场景包括社交网络中的转发预测、疫情传播预测、地震余震预测、金融市场订单预测、推荐系统中的用户行为预测等。
因果发现则更关心事件之间的影响结构。例如在神经科学中,多个神经元的 spike train 可以被视为多变量点过程,研究者希望推断神经元之间是否存在功能连接;在高频金融中,买单和卖单之间的相互影响可以用 Hawkes 过程刻画;在 AIOps 中,系统故障事件的触发关系有助于定位根因;在医疗和网络安全中,事件依赖结构也能帮助理解复杂系统中的传播机制。
这也是 TPP 区别于一般序列预测模型的重要价值: 它不仅试图预测未来,还试图回答「过去的哪些事件以何种方式影响了未来」。
未来挑战:可解释性、可扩展性、采样效率和多模态
论文最后总结了 TPP 领域仍待解决的几个核心挑战。
第一是数据和模型标准化。 事件序列通常具有不规则时间间隔、变长序列、多样 mark 空间和不同时间粒度。不同数据处理方式会显著影响模型表现,也会让论文间比较变得困难。
第二是模型可解释性。 传统 Hawkes 模型中的背景强度和触发函数有明确含义,而神经 TPP 往往把动态编码进高维隐状态中,难以解释过去事件如何影响未来强度。在因果发现、科学建模和决策支持中,这一问题尤其关键。
第三是可扩展性。 真实事件流可能包含数万甚至更多时间戳,而模型还要处理连续时间积分、长程依赖和多类型事件交互。简单把 Transformer 换成 Mamba 或其他高效模块还不够,未来需要理解这些架构如何表示 hazard function、历史依赖和长期时间因果。
第四是采样效率。 经典 thinning 或 inverse transform sampling 需要反复评估强度函数,对复杂神经模型来说代价很高。扩散模型、flow-based 方法、speculative decoding 等方向正在尝试并行或块状生成事件序列,但仍需平衡时间一致性、条件结构和计算成本。
第五是多模态建模。 真实事件往往伴随文本、图像、视频帧、传感器读数等上下文信息。LLM 和多模态大模型为这类问题提供了新工具,但也带来时间对齐、不确定性校准、可控生成等新问题。
结语:TPP 正在从「预测事件时间」走向「理解事件世界」
这篇 TMLR 综述传递出的一个重要信号是: TPP 正处在一个重新汇合的阶段。 统计学传统提供了强度函数、似然、贝叶斯推断和因果解释;深度学习提供了强大的表示能力和端到端预测能力;大语言模型则把文本、知识、多模态和推理能力带入事件序列建模。
未来的 TPP 可能不再只是一个预测「下一个事件何时发生」的模型,而是一个能够理解连续时间中复杂事件流的通用框架。它既要知道时间,也要理解语义;既要能预测,也要能解释;既要足够灵活,也要保留统计建模中的可校准性和可靠性。
对机器学习研究者来说,这意味着 TPP 不是一个偏门的统计工具,而是连接连续时间建模、序列学习、因果发现和大模型推理的重要交叉点。 而这篇综述的价值,正在于它把这些正在分散发展的线索重新放回了一张图里。