
LLM近期重大架构进化一览:从Gemma 4到DeepSeek V 4
过去一段时间,很多人对大模型都有一个明显感受: token 总是不够用 。
毕竟用户想大模型更 「聪明」 更连贯,上下文窗口只会越来越大。
而在模型背后,长上下文是相当「奢侈」的。用户 token 消耗翻倍,其实是模型更大的 KV cache 和更高的 attention 计算成本。
尤其是在推理模型和 Agent 逐渐成为主流后,长上下文已经从一个「宣传亮点」,逐渐转变为大模型架构设计需要正面解决的问题。
Sebastian 精准地捕捉到,最近几个月发布的一批 LLM,正好体现了这个趋势。
从 Google 的 Gemma 4,到 Poolside 的 Laguna XS.2、Zyphra 的 ZAYA1-8B,再到 DeepSeek V4, 这些模型在 Transformer 内部做了各种「省钱设计」,试图围绕长上下文推理降低计算和存储成本 。
Sebastian 为此发布了技术博客,以下为博客链接与全文翻译。
 博客标题:LLM 架构的最新发展:KV 共享、mHC 与压缩注意力
博客标题:LLM 架构的最新发展:KV 共享、mHC 与压缩注意力
博客链接:https://magazine.sebastianraschka.com/p/recent-developments-in-llm-architectures
Gemma 4:
通过跨层复用 KV Tensor 缩小 KV Cache
时间回到四月初,Google 发布了全新的开源权重模型系列 Gemma 4。整个系列大致可以分为三类:
面向移动端与小型本地(嵌入式)设备(即 IoT)的 Gemma 4 E2B 与 E4B;
面向高效本地推理、采用混合专家架构(MoE)的 Gemma 4 26B;
以及采用 Dense 架构、追求更高模型质量与更便捷后训练流程的 Gemma 4 31B(因为 MoE 模型通常更难进行后训练和调优)。
 Gemma 4 架构示意图 Gemma 4 E2B 与 E4B 的第一个小型架构改动,是采用了「共享 KV Cache」机制:后续层会复用前面层已经计算出的 Key-Value 状态,从而降低长上下文场景下的显存占用与计算成本。
Gemma 4 架构示意图 Gemma 4 E2B 与 E4B 的第一个小型架构改动,是采用了「共享 KV Cache」机制:后续层会复用前面层已经计算出的 Key-Value 状态,从而降低长上下文场景下的显存占用与计算成本。
这种方法并不是 Gemma 4 首创。例如 NeurIPS 2024 的论文《Reducing Transformer Key-Value Cache Size with Cross-Layer Attention》已经提出类似思路。但 Gemma 4 是第一次将其大规模应用于主流开源架构中。
为什么 KV Cache 如此重要?
正如我最近几个月不断提到的,当前 LLM 架构设计中的一个核心主题,就是 「缩小 KV Cache」 。而缩小 KV Cache 的根本目的,是降低模型运行所需的显存占用,从而支持更长的上下文窗口。这一点在推理模型和 Agent 时代尤其重要。
举一个经典的例子(Gemma 4 目前依然在使用):Grouped Query Attention(GQA)本身就已经通过让多个 Query Head 共享同一组 Key-Value(KV)Head,来减少 KV Cache 的大小,如下图所示。
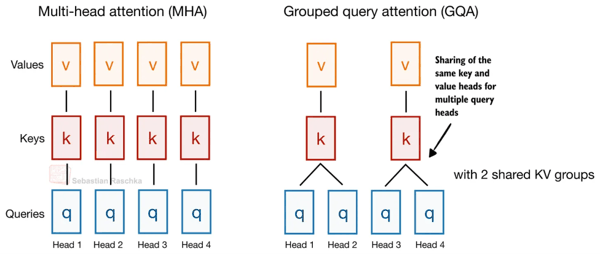
Gemma 4 的跨层 KV 共享机制
如前所述,Gemma 4 使用了 GQA。不过,除了 GQA 中不同 Query Head 之间的 KV 共享之外,Gemma 4 还进一步 在不同 Transformer Layer 之间共享 KV Projection,而不是像传统做法那样,在每一层 Attention 模块中分别计算自己的 KV 。
这种 KV 共享机制也被称为 Cross-Layer Attention,其结构如下图所示。
 正如架构示意图中所提到的,Gemma 4 E2B 采用了普通 GQA 与 Sliding Window Attention 按照 4:1 的方式组合使用。(更准确地说,Gemma 4 E2B 实际使用的是 MQA,也就是 GQA 中只有一个 KV Head 的特殊情况。)
正如架构示意图中所提到的,Gemma 4 E2B 采用了普通 GQA 与 Sliding Window Attention 按照 4:1 的方式组合使用。(更准确地说,Gemma 4 E2B 实际使用的是 MQA,也就是 GQA 中只有一个 KV Head 的特殊情况。)
在 GQA(或 MQA)机制下,KV 共享的方式如下:后续层不再单独计算自己的 Key 和 Value Projection,而是直接复用最近一个、同类型且未共享层所生成的 KV Tensor。
换句话说:Sliding Window Attention 层会复用前面某个 Sliding Window 层的 KV, Full Attention 层则会复用前面某个 Full Attention 层的 KV。
当然,每一层仍然会计算自己的 Query Projection,因此不同层依然可以形成各自不同的 Attention Pattern;但代价最高、最占显存的 KV Cache,则会被多个层共同复用。例如:
Gemma 4 E2B 一共有 35 层 Transformer Layer,但只有前 15 层会真正计算自己的 KV Projection;后面的 20 层则直接复用之前同类型层的 KV Tensor。
类似地,Gemma 4 E4B 共 42 层,其中 24 层负责计算 KV,最后 18 层采用共享机制。
这种设计到底能节省多少资源?
由于大约有 一半 的 KV 在不同层之间被共享,因此 KV Cache 的整体大小也大致减少了一半。对于最小的 E2B 模型来说,在 128K 长上下文、bfloat16 精度下,可以节省约 2.7GB 显存;而 E4B 在同样条件下,则大约能够节省 6GB 。
 Gemma 4 E2B 类似配置中,GQA 与跨层 KV 共享带来的 KV Cache 显存节省效果 当然,KV Sharing 的缺点在于,它本质上是一种对完整 Attention 计算的「近似」。更准确地说,它会削弱模型容量。
Gemma 4 E2B 类似配置中,GQA 与跨层 KV 共享带来的 KV Cache 显存节省效果 当然,KV Sharing 的缺点在于,它本质上是一种对完整 Attention 计算的「近似」。更准确地说,它会削弱模型容量。
不过,根据 Cross-Layer Attention 论文中的实验结果,在被测试的小规模模型上,这种影响可以非常有限。
Gemma 4 E2B / E4B:
Per-Layer Embeddings(PLE)与「有效参数量」
Gemma 4 的 E2B 与 E4B 版本还引入了第二种以效率为导向的设计: Per-Layer Embeddings(PLE,逐层嵌入) 。这一机制与前面提到的 KV Sharing 是相互独立的。
KV Sharing 的目标是缩小 KV Cache,而 PLE 关注的则是参数效率(parameter efficiency):它让小尺寸的 Gemma 4 模型能够携带更多 token-specific information(与 token 相关的特征信息),但又不会让整个 Transformer 主干像同参数量 Dense 模型那样昂贵。
例如,Gemma 4 E2B 与 E4B 中的「E」,代表的就是「effective」(有效参数量) 。具体来说:
Gemma 4 E2B 标注为 2.3B effective parameters,但如果把 embedding 参数也算进去,总参数量实际上达到 5.1B;
Gemma 4 E4B 的 effective parameters 为 4.5B,而包含 embedding 后则约为 8B。
换句话说,在这些 「E」系列模型中,真正负责主要计算的 Transformer Stack,其计算规模更接近前面的较小数字;而后面的总参数量,则包含了额外的 embedding table。
从概念上来看,PLE 的结构大致如下:
 带有 PLE residual path 的简化版 Gemma 4 Block。普通 Transformer Block 会先完成 Attention 与 Feed-Forward 的 residual update;随后,生成的 hidden state 会作为 gating 信号,控制 layer-specific 的 PLE vector,并在 Block 末尾额外加入一次 projected PLE residual update。
带有 PLE residual path 的简化版 Gemma 4 Block。普通 Transformer Block 会先完成 Attention 与 Feed-Forward 的 residual update;随后,生成的 hidden state 会作为 gating 信号,控制 layer-specific 的 PLE vector,并在 Block 末尾额外加入一次 projected PLE residual update。
PLE Vector 本身是在 Transformer Block 外部提前构建的。简单来说,它有两个输入来源:token ID 经过 per-layer embedding lookup; 普通 token embedding 再通过一个 linear projection,映射到同一个 PLE 空间。
随后,这两部分结果会被相加、缩放,并 reshape 成一个 tensor,其中每一层都对应一个独立 slice,而每个 Transformer Block 只会接收属于自己的那一份。
 简化版 PLE(Per-Layer Embeddings)构建流程 这里有一个很重要的细节:PLE 并不是给每个 Transformer Block 单独复制一整套 embedding layer。相反,per-layer embedding lookup 只会计算一次,然后再给每一层分发一个较小的 token-specific embedding slice。
简化版 PLE(Per-Layer Embeddings)构建流程 这里有一个很重要的细节:PLE 并不是给每个 Transformer Block 单独复制一整套 embedding layer。相反,per-layer embedding lookup 只会计算一次,然后再给每一层分发一个较小的 token-specific embedding slice。
因此,对于每个输入 token,Gemma 4 会提前准备一个 packed PLE tensor,其中包含每一层 decoder 对应的一小段 embedding vector。
真正进入 Transformer Block 后,Attention 与 Feed-Forward 分支仍然按正常方式运行。在完成 Feed-Forward residual update 后,当前 hidden state(图中记作 z)会用于 gate layer-specific PLE vector。被 gate 后的 PLE vector 会重新投影回 model hidden size、做 normalization,并作为额外 residual update 加回模型中。
一个比较直观的理解方式是 Transformer Block 的主体结构并没有改变, Gemma 4 只是额外在 Feed-Forward 分支后面,插入了一小段「层特定 token 向量」 。这样做能够通过 embedding 参数与小规模 projection,提升模型的表达能力,同时避免把整个 Transformer Stack 都扩展到更大的参数规模。
为什么要用 PLE?
一种更直接的方法,其实是简单缩小 Dense 模型,比如减少层数、缩小 hidden state 或缩小 Feed-Forward Network。
这样当然能降低显存与延迟,但也会直接削弱模型真正负责计算的核心部分。
而 PLE 的思路则是: 让昂贵的 Transformer Block 保持在较小的 「effective size」,同时把额外容量存储在 per-layer embedding table 中 。由于 embedding 本质上主要是 lookup-style parameter,它们远比增加 Attention 或 FFN 权重更便宜,也更容易缓存。
当然,目前我们还只能相信 Google 的实验结果,认为这确实是一个有效的设计。作者也提到,未来如果能看到更多对比实验,例如:PLE 版 Gemma 4 E2B vs 普通 2.3B Dense 模型 vs 普通 5.1B Dense 模型 。
这样的对比会非常有意思。
此外,从理论上讲,PLE 并不只适用于小模型。更大的模型同样可以加入 per-layer embedding slice。但由于大模型本身已经具有足够容量,因此这些额外 embedding 的收益可能不再明显。而且在大模型中,我们通常已经通过 MoE 等结构,在不显著增加计算量的前提下提升模型容量。
Laguna XS.2:
Layer-wise Attention Budgeting
Laguna 是欧洲公司 Poolside 推出的首个 open-weight 模型,Poolside 主要专注于面向代码场景的 LLM 训练。
不同 Layer 使用不同 Attention Budget。
下图中的 Laguna XS.2 架构乍一看其实相当标准。不过,有一个我没有画进去(或者说没法硬塞进图里)的细节,是一个可以称为 「Layer-wise attention budgeting」 的概念。