
哈萨比斯出的难题,GPT之父接上了:用一个知识停在1930年的模型
「 一个训练数据截止到 1911 年的模型,能不能自己推导出爱因斯坦 1915 年提出的广义相对论 ?」今年年初,哈萨比斯给出了一个极其硬核的 AGI 判定标准。
没想到的是,这件事真的有人尝试去做了,而且其中一位作者还是 GPT 之父 Alec Radford。
最近,Alec Radford 和「神经常微分方程」提出者之一、陈天琦导师 David Duvenaud 以及量化专家 Nick Levine 一起做了一个有趣的项目:用 1931 年以前的数据训练了一个 13B 模型 ——Talkie,然后和这个模型对话,看看会发生什么有意思的事情。
这个「来自 1930 年」的模型被切断了所有现代知识的污染。这给了研究者一个罕见的机会:当你想测试一个 AI 到底是真的理解了某些能力,还是仅仅在重复训练数据里的答案,talkie-1930 就是那个诚实的参照系(理论上是)。对于哈萨比斯提出的问题,这也是一个很好的探索起点。
来自 1930 年的模型,有什么用?
talkie 的训练数据,全部来自 1931 年以前的英文文本,包括书籍、报纸、期刊、专利、法律文书,总计 2600 亿个 token。之所以选这一年作为截止点,是因为在美国,在此之前的作品已进入公共领域,可以合法使用。
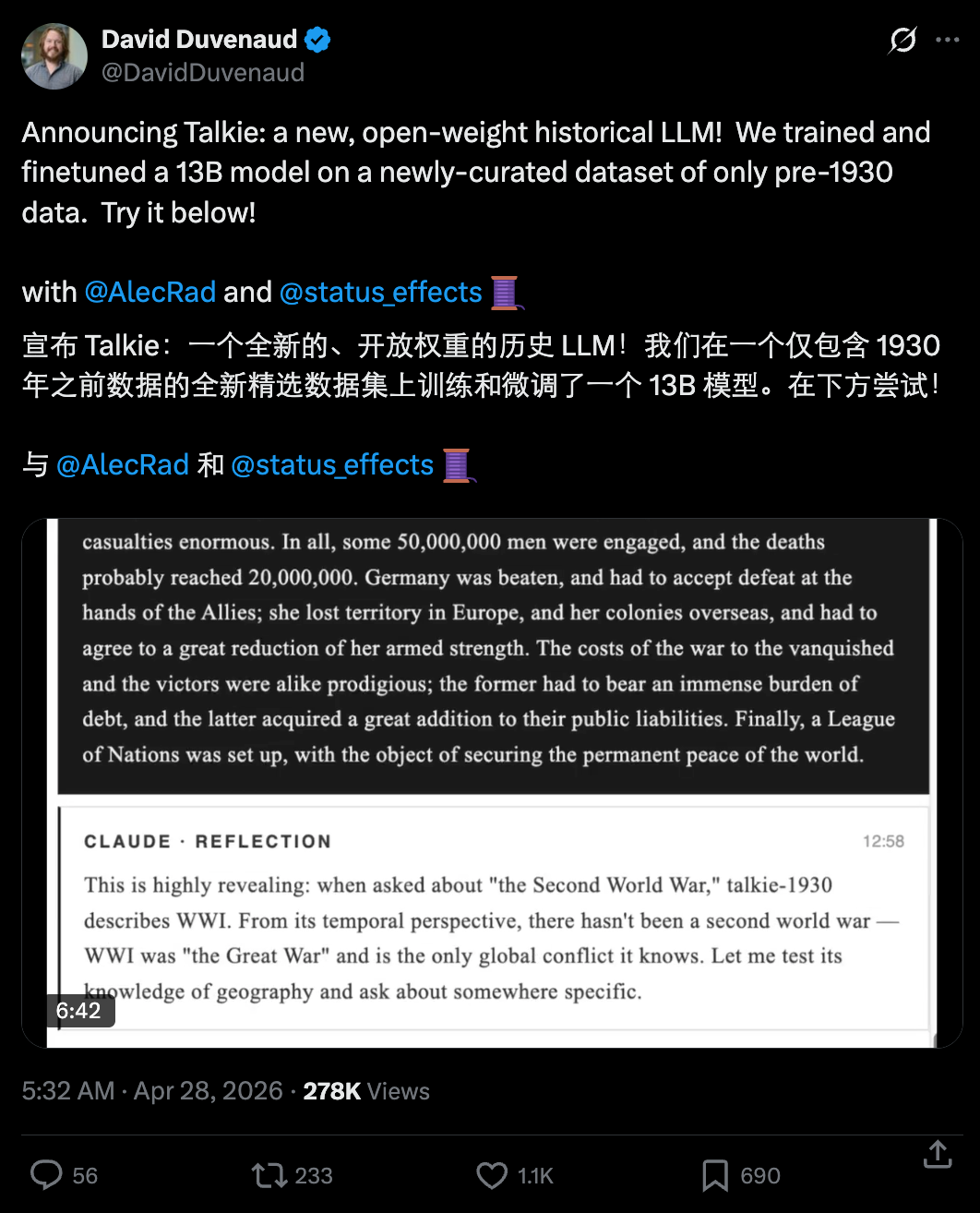
模型训练好之后,研究者们做了一件很有趣的事:他们开了一个 24 小时的直播频道,让 Claude Sonnet 4.6 全天候地去和 talkie‑1930 聊天,探索这个「古人」的知识边界。对话记录是公开的,大家看看怎么样。
其他人也可以试用这个模型,以下是我们问的两个简单的小问题。
体验链接:https://talkie-lm.com/chat
但更有意思的,不是模型具体表现,而是研究者们为什么要这么做。
他们提出了一个问题:一个只活在过去的模型,能在多大程度上「预感」到未来?
他们从《纽约时报》的「历史上的今天」栏目里抓了将近 5000 条历史事件的描述,然后测量这些描述对 talkie 来说有多「意外」。用信息论的语言说,就是每字节文本的惊讶度。结果正如预期的那样:1930 年之前的事,talkie 不觉得意外;1930 年之后,惊讶度明显爬升,在五六十年代达到顶峰,之后趋于平稳。
这套方法背后藏着一个更野心勃勃的设想。研究者们引用了 DeepMind 创始人 Demis Hassabis 曾经提出过的问题(如前所述),他们还举了几个类似的例子:西科斯基的直升机专利(1935 年)、图灵关于可计算数的论文(1936 年)、卡尔森的静电复印专利(1942 年)—— 这些都是 talkie「理论上」无法知晓的东西。但 如果模型足够大、理解足够深,能不能凭借对已有知识的推演,自己走到那一步 ?
这个问题目前还没有答案,但已经足够让人认真想一想了。
他们提出的第二个动机,是污染问题。
评估大模型能力,有一个长期困扰研究者的麻烦:你怎么知道模型是真的「会」,而不是在训练数据里见过这道题的答案?这个问题几乎无解,因为现代模型的训练数据实在太庞大,根本没法逐一排查。
talkie 天然绕开了这个问题。它完全不知道 Python 是什么,也从未见过任何一行现代代码。于是研究者们做了一个实验 —— 用 HumanEval 这套标准编程测试来评估它。他们给 talkie 随机挑选几个 Python 函数作为示例,然后让它自己写一个新的出来,看它能在 100 次尝试中至少答对一次的比例有多高。
结果是:talkie 确实能学,而且随着规模的扩大,模型在这项任务上的表现会缓慢但稳定地提升。
但比起训练在现代网页数据上的同等规模模型,talkie 还有很大差距。而且,它答对的题目全都属于两类:要么是极简单的单行程序,要么是对示例程序的小幅改动。研究者们特别提到了一个例子 —— 一个旋转密码的解码函数。示例里给了编码函数,talkie 理解了「逆操作」的概念,把加号换成减号,一字之差,答案正确。他们认为,这说明模型对「逆函数」这个抽象概念有所理解,而不只是在照猫画虎。
一个对数字计算机一无所知的模型,依然能从示例里摸索出编程的逻辑。这个结果让研究者们觉得值得继续往下做。
第三个动机,是关于 数据多样性 的一个更深层的问题。
当今所有主流大模型,无论是 GPT、Claude、还是 Gemini,训练数据最终都指向同一个来源:互联网。直接爬取也好,蒸馏也好,合成数据也好,本质上都是同一片信息海洋的产物。这就引出了一个值得认真对待的问题:我们以为自己在研究「语言模型的普遍规律」,实际上研究的,会不会只是「训练在互联网上的模型」的特殊性质?这些模型在气质、能力和行为倾向上的相似,到底有多少来自人类语言和文化的共性,又有多少只是因为喝了同一口井里的水?
talkie 提供了一个对照组。通过研究它与现代模型的异同,研究者们希望剥离出哪些特征是语言模型的普遍属性,哪些是「互联网训练」的特有产物。
为了更直观地衡量 talkie 的能力,研究者们还专门训练了一个「现代孪生」模型 —— 架构完全一样,只是把训练数据换成了现代网页数据集 FineWeb。两个模型在语言理解、数字计算和知识掌握三个维度上正面比较。
结果是 talkie 全面落后。但研究者们注意到一个细节:测试题里有很多问题,对一个只知道 1930 年以前世界的模型来说,本身就是「超纲」的 —— 它没有理由知道那些事。把这些题目过滤掉之后,两个模型之间的差距大约缩小了一半。