
从平面修图到空间重塑:京东开源图像模型JoyAI-Image-Edit重新定义AI编辑
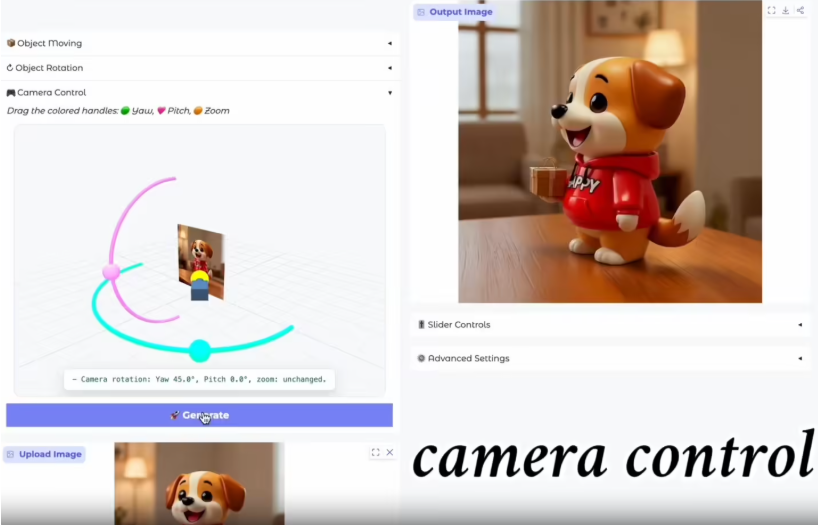
京东探索研究院近日宣布,正式开源自研的JoyAI-Image-Edit图像模型,标志着AI修图技术从传统的平面处理跨入三维空间建模的新阶段。作为业内首个强调“空间智能”的开源模型,它赋予了AI真正理解并重塑物理空间的能力。
深度建模三维空间
该模型深度贴合现实世界的物理规律,从相机感知到物体位移等维度进行全面建模。这使得开发者能够直接调用推理代码,在保持场景几何一致性的基础上实现精准的空间编辑。
JoyAI-Image-Edit攻克了开源界长久以来的空间理解难题,具备 极高 的辨识度。其核心亮点在于能够根据自然语言指令,灵活调整相机的偏航角、俯仰角及缩放比例。
赋能多元应用场景
不仅如此,模型还支持连续的视角移动,能生成逻辑连贯的漫游序列。在保持整体结构稳定的同时,它还可以对特定物体进行缩放或位移,并确保光影遮挡关系自然。
除了突破性的空间能力,该模型还全面兼容包括物体增删、风格迁移在内的 15 类通用编辑需求。目前,它已广泛应用于电商生产、创意设计及具身智能等前沿领域,为行业提供了关键的底层技术支撑。
相关推荐
京东开源图像模型JoyAI-Image-Edit:达到世界一流水平
京东探索研究院近日开源了自研的JoyAI-Image-Edit图像模型,其核心突破在于能理解图像的三维空间结构,解决了传统AI修图空间逻辑混乱的问题。该模型具备三大空间编辑能力:视角变换、空间漫游和物体空间关系操控,并兼容15类通用编辑功能。应用场景广泛,尤其在具身智能领域,可为机器人理解世界提供关键底层能力。京东近期在AI领域动作频频,持续推动AI与产业深度融合。
0420自助KTV 3.0时代巨嗨发布会:重新定义“服务边界”与“系统逻辑”
4月20日,厦门将举办自助KTV3.0时代行业标准发布会。文章指出,真正的“时代”意味着行业多数人仍用旧逻辑解决问题时,少数人已找到更优解,并验证其可行、可复制、可持续。巨匠团队通过全国调研发现,行业问题并非“设备不够多”,而是“系统不够懂”——需理解老板成本压力、年轻人社交需求、投资人资产焦虑及门店运营细节。自助KTV3.0核心是从“人管店”转向“系统管店”,通过AIoT智能系统替代重复低效工作,实现人力成本大幅降低。同时,年轻消费者要的不是“唱歌的地方”,而是“能晒的地方”,追求体验与被关注感。3.0方案让包厢根据用户偏好预设氛围,全程无打扰,设备通过AI智能协同,减少数量、缩短安装周期、降低运维成本,实现“轻设备、轻运维”。投资逻辑从“看位置”转向“先看产品”,包厢作为可移动、可变化的资产单元,支持48小时闪电落地,品牌随需而变。发布会旨在通过实测数据、落地门店和智能系统,清晰呈现自助KTV3.0时代标准。